This is an update on our experimental project called Declarative Gradle. We have just released a new Early Access Preview (EAP) that incrementally improves support for new datatypes in the Declarative Configuration Language (DCL) and makes it possible for simple real-world projects to try Declarative Gradle.
Declarative Gradle is part of our vision to deliver an elegant and extensible declarative build language that allows developers to describe any kind of software in a clear and understandable way. We think it will offer a fundamental advancement in the Gradle user experience and tooling capabilities for software developers.
Our first EAP release in July 2024 introduced a configuration model called Software Types, described a new configuration language, and demonstrated...
As Gradle 9.0 approaches, we’re sharing updates on the Configuration Cache—a key feature that significantly improves configuration time for large projects. In this major release, we plan to make the Configuration Cache the preferred execution mode, with the goal of enabling it by default in Gradle 10.0.
The Configuration Cache is one of Gradle’s most anticipated features; progress has been substantial. As Gradle Fellow Tony Robalik noted:
“I’m excited about all the work Gradle has done to make the Configuration Cache stable and the preferred mechanism for running builds. At work, we’ve observed that enabling Configuration Cache globally will recover roughly 4 years of lost engineering time annually. The configuration cache also lays the foundation for Isolated Projects, which...
A year ago, we announced a new experimental project called Declarative Gradle. That blog post presented our vision for a declarative model for Gradle. It also introduced our concept of a developer-centric software definition. This was followed by the first Early Access Preview release in July 2024, accompanied by the First Look at Declarative Gradle blog post. The first EAP introduced a configuration model called Software Types, a new Declarative Configuration Language (DCL), and demonstrated the potential for tooling improvements and better IDE support.
It is now easier to try Declarative Gradle. The first EAP was based on separate Declarative Gradle prototype plugins. These prototype plugins implement Software Types wrapping existing plugins like Android Gradle Plugin (AGP)...
In our update in November 2023, we announced a new experimental project called Declarative Gradle. That post introduced our ideas for a developer-first software definition and how we planned to fulfill our vision for a declarative build language for Gradle. Since then, we’ve been working hard to create the first early access preview (EAP) of Declarative Gradle.
This blog post provides an update on the project’s progress and outlines how you can try it out, provide feedback, and influence our next steps.
What is Declarative Gradle?
Part of our vision for Gradle Build Tool is to deliver an elegant and extensible declarative build language...
At Devoxx France, we sat down with Louis Jacomet, a tech lead at Gradle Inc. Louis leads the Gradle Build Tool support team and coordinates releases, so you can often see him active on GitHub issues and speaking at Gradle conferences. Let’s dive into what Louis shares about the upcoming Gradle 9 release!
A Busy Day at Devoxx FR
Louis had a packed schedule on Friday at Devoxx FR, with 4 hours of talks lined up. He did a session with Hervé Boutemy from the Apache Maven community on navigating the labyrinth of dependency management, which was a 1-hour talk. He also had a separate discussion with his colleague Paul Merlin about the upcoming features in...
Gradle is happy to announce a technical partnership with GitHub focusing on multiple areas, starting with supply chain security and developer experience. With this partnership, we establish a direct connection between organizations and plan to cooperate on integrations between GitHub and Gradle to promote best security practices among Gradle users.
The first feature being released as a part of this partnership is the dependency submission GitHub Action for Gradle, which can be configured to automatically submit dependencies to GitHub’s dependency graph, helping users better understand their application and receive Dependabot alerts.
This partnership will improve the experience of many users within the shared Gradle and GitHub ecosystem. GitHub is the world’s leading AI-powered developer platform to build, scale, and deliver secure software,...
NOTE: Declarative Gradle is an experimental project undergoing active development, with frequent changes occurring during implementation. To learn more about the current status, visit the Declarative Gradle repository on GitHub. Here, you can access the current documentation, prototypes. Subscribe to the Gradle Build Tool Newsletter to receive monthly updates on the project - last updated on May 11, 2024
Part of our vision for Gradle Build Tool is to deliver an elegant and extensible declarative build language that allows developers to describe any kind of software in a clear and understandable way.
Gradle’s build language is already extensible in the most fundamental ways, which results in a high degree of flexibility. This is one of the main reasons...
The configuration cache is a feature that significantly improves build performance by caching the result of the configuration phase and reusing it for subsequent builds. Using the configuration cache, the Gradle Build Tool can skip the configuration phase entirely when nothing that affects the build configuration, such as build scripts, has changed.
In Gradle 8.1, the configuration cache became stable and recommended for adoption. Stability, in this case, means that the behavior is finalized, and all breaking changes follow the Gradle deprecation process. In general, if something works now, it will continue to work the same way—unless the behavior is buggy and may lead to incorrect builds. While some features are not yet implemented, most users can already benefit...
In this blog post, we will explain what lazy property assignment is and how you can take advantage of the new syntax in the latest Gradle release.
What is the lazy property API?
The lazy property API is a Gradle feature that delays the calculation of a property’s value until its required. This is the recommended way of writing properties for extensions and tasks.
Some of the provided benefits include:
Solving configuration ordering issues (no more Project.afterEvaluate())
Tracking dependencies automatically (no need for Task.dependsOn())
As projects grow in size and complexity and otherwise mature, they tend to accumulate a large collection of automated tests. Testing your software at multiple levels of granularity is important to surface problems quickly and to increase developer productivity.
In Gradle 7.3, released November 2021, the Gradle team introduced a new feature called Declarative Test Suites. Using this feature makes it much easier to manage different types of tests within a single Gradle JVM project without worrying about low level “plumbing” details.
Why Test Suites?
Normally - whether or not you’re practicing strict Test Driven Development - as you develop a project you will continuously add new unit tests alongside your production classes. By convention, for a Java project,...
Building a Java project and running Gradle both require the installation of a JDK. Most Gradle users conveniently use the Java installation that is running Gradle to build and test their application.
While this is acceptable in simple cases, there are a number of issues with this approach. For example, if a build requires the same Java version to be used on all machines, each developer needs to know about that requirement and install that version manually.
It has been possible to configure Gradle to build a project with a different Java version than the one used to run Gradle. However, it has required configuring each task like compilation, test, and javadoc separately.
Gradle 6.7 introduces “Java toolchain support”. In a nutshell,...
This is the second installment in a series of blog posts about incremental development — the part of the software development process where you make frequent small changes. We will be discussing upcoming Gradle build tool features that significantly improve feedback time around this use case. In the previous post, we introduced file system watching for Gradle 6.5.
In Gradle 6.6 we are introducing an experimental feature called the configuration cache that significantly improves build performance by caching the result of the configuration phase and reusing this for subsequent builds. Using the configuration cache, Gradle can skip the configuration phase entirely when nothing that affects the build configuration, such as build scripts, has changed.
This is the first installment in a series of blog posts about incremental development–the part of the software development process where you make frequent small changes. We will be discussing upcoming Gradle build tool features that significantly improve feedback time around this use case.
This blog post has been updated after the feature has become production-ready in Gradle 6.7.
In Gradle 6.5, we have introduced an experimental feature called file system watching that significantly accelerates incremental builds. When enabled, it allows Gradle to keep what it has learned about the file system in memory between builds instead of polling the file system on each build. This significantly reduces the amount of disk I/O needed to determine what has changed since the...
One of the biggest challenges when dealing with transitive dependencies is to keep their versions under control. Popular libraries will show up as transitive dependencies in multiple places in your dependency graph. And it is quite likely that the version information will be different on each path.
Through multiple blog posts, you have learned that Gradle offers a rich feature set for expressing complex dependency requirements. In this post, we will discuss why semantics matter when downgrading a dependency version. And you will learn about the strict version feature of Gradle 6 that provides this semantic information and effectively gives you a powerful and precise tool for dealing with this complex issue.
More than 10 years ago, a new Java collections library was released by Google.
This library, now known as Google Guava, would gain a lot of traction over the months and years and is possibly the most used Java library in production code today.
Due to the widespread adoption of Guava, many other libraries depend on it today.
Chances are high that you will find it on the classpath of any reasonably large Java project through transitive dependencies, even if it is not used directly.
With more and more code depending on such a widely used library, the potential for conflicts increases, adding to a project’s dependency hell.
This post introduces a new Gradle plugin and build scans improvements aimed at mitigating your flaky tests.
Flaky tests disrupt software development cycles by blocking CI pipelines and causing unnecessary failure investigations. Unhealthy teams live by re-running builds, sometimes several times, to get changes through. Martin Fowler has pointed words about non-deterministic tests that are worth a read.
To eliminate this parasite from your organization you have to identify, prioritize, and fix your flaky tests.
Mitigating flaky tests
There are a number of clever heuristics that help identify flaky tests. You could run some static analysis to prove that a test failure could theoretically not cause a given test failure. You could count the number of “flips” from failed...
In a previous blog post, we demonstrated how capabilities could be used to elegantly solve the problem of having multiple logging frameworks on the classpath. In this post, we will again use this concept in a different context: optional dependencies.
At Gradle, we often say that there are no optional dependencies: there are dependencies which are required if you use a specific feature. Let’s explain why.
Optional dependencies
Until recently, Gradle didn’t offer any way to publish optional dependencies, which is something which puzzled a number of Apache Maven™ users. To understand in what context optional dependencies are used, let’s look at a real world project. The Apache PDFBox library declares the following optional dependencies in its ❯ Read more
Gradle 6.0 comes with a number of improvements around dependency management that we present in
a series of blog posts.
In this post we explore the detection of incompatible dependencies on the classpath, through the concept of capabilities.
In order to illustrate this concept, we will look at the state of logging for Java applications and libraries.
Aside from the Java core libraries providing java.util.logging (JUL), there are a number of logging libraries available to developers, for example:
This blogpost has been updated to reflect that Jackson started to published Gradle Module Metadata with version 2.12.0 using the recommendations from this post.
In the previous post about dependency management with Gradle 6, we saw that growing builds can quickly end up in dependency hell. Unexpected results become particularly hard to analyze if they are introduced at the bottom of the dependency graph and propagate up through transitive dependencies. It is unfortunate that some of these issues could be avoided if the authors of libraries, which form the bottom of the dependency graph, had the means to express all the knowledge about the versioning of said libraries in the libraries’ metadata.
Dependency hell is a big problem for many teams. The larger the project and its dependency graph, the harder it is to maintain it. The solutions provided by existing dependency management tools are insufficient to effectively deal with this issue.
Gradle 6 aims at offering actionable tools that will help deal with these kind of problems, making dependency management more maintainable and reliable.
Take, for example, this anonymized dependency graph from a real world project:
There are hundreds of different libraries in this graph. Some are internal libraries, some are OSS libraries. A proportion of those modules see several releases a week. In practice, with a graph of this size, there’s no way you can...
This post introduces some new native plugins that we’ve been working on that can build Swift libraries and applications.
They work on both macOS and Linux with the official Swift compiler.
As the new C++ plugins are getting more attention from early adopters, we want to update everyone on their progress since our previous Introducing the new C++ plugins post.
The last few months have seen several new features, new and expanded documentation, and improvements in IDE support.
If you work with Eclipse you are probably familiar with Buildship, the Eclipse plugins for Gradle. The Buildship 3.1 release allows you to run tasks upon project synchronization and auto build, the two most highly voted issues on Github. In this post, we’re going to summarize why this is an essential feature for many and how can you make use of it.
Extending project synchronization
The Buildship project synchronization functionality imports the Gradle projects into the workspace and configures them to work with the Java toolchain. That - of course - is just the tip of the iceberg. There are many other tools and frameworks out there, and Buildship can’t provide configuration for all. Since 3.0, there’s a ❯ Read more
Gradle Module Metadata reaches 1.0 in Gradle 5.3 and here we explain why you should be as excited as we are!
Gradle Module Metadata was created to solve many of the problems that have plagued dependency management for years, in particular, but not exclusively, in the Java ecosystem. It is especially important because POM files (or Ivy files) are simply not rich enough to describe the reality of software nowadays where you might need to distinguish between binaries for different platforms or choose one particular implementation of an API when more than one is available.
We will describe more examples later in this post. Some issues may have workarounds, but where those workarounds are hacky ones or even error prone. For example,...
We want you to enjoy a build authoring experience with the benefits provided by Kotlin’s static type system in Intellij IDEA and Android Studio: auto-completion, smart content assist, quick access to documentation, navigation to source and context-aware refactoring.
This post introduces a new Gradle dependency management feature called “source dependencies”.
Normally, when you declare a dependency on a library, Gradle looks for the library’s binaries in a binary repository, such as JCenter or Maven Central, and downloads the binaries for use in the build.
Source dependencies allow you to instead have Gradle automatically check out the source for the library from Git and build the binaries locally on your machine, rather than downloading them.
We’d love to get your feedback on this feature. Please try it out and let us know what works for you and any problems you run into. You can leave feedback on the Gradle forums or raise issues on the Gradle native GitHub repository.
We want you to enjoy a build authoring experience with the benefits provided by Kotlin’s static type system: context-aware refactoring, smart content assist, debuggable build scripts, and quick access to documentation. In case you haven’t seen it, you can watch Rodrigo B. de Oliveira demonstrate these benefits in this KotlinConf 2017 video.
Kotlin DSL 1.0 final will be released with Gradle 5.0, which is the next version of Gradle. After version 1.0, the Kotlin DSL will not introduce any more breaking changes without a deprecation cycle.
Please try the Kotlin DSL and submit feedback. Guidance for doing that...
This post introduces a new API for declaring and configuring Gradle Tasks in build scripts and plugins. We intend for this new API to eventually replace the existing API because it allows Gradle to avoid configuring unnecessary build logic. Use of the new API will become the default recommendation soon, but the existing API will go through our usual deprecation process over several major releases.
We are asking early adopters to try out the new Gradle Tasks API to iron out any issues and gather feedback. We’ve created a new user manual chapter to give a quick introduction to the feature and explains some guidelines for migrating your build to use the new API.
This post introduces some new plugins for C++ that we’ve been working on. These plugins can build C++ libraries and applications. They work on macOS, Linux, and Windows with GCC, Clang and Visual C++/Visual Studio.
We welcome any feedback you may have about these plugins. You can leave feedback on the Gradle forums or raise issues on the Gradle native GitHub repository.
We’ve received many inquiries about the status and direction of Gradle’s Software Model, especially from users building native libraries and applications.
In this blog post, we will explain the current state and future of the Software Model, and in particular how it relates to native development with Gradle. A lot of exciting improvements are planned for the remainder of 2017; see the roadmap below.
Situation with the Software Model
In a nutshell, the Software Model is a very declarative way to describe how a piece of software is built and the other components it needs as dependencies in the process. It also provides a new, rule-based engine for configuring a Gradle build. When we started to implement the Software Model we set ourselves the following goals:
At Google I/O today, the Android Studio team released the first preview version of the Android Gradle plugin 3.0, based on Gradle 4.0 M2. It brings major performance improvements, especially for builds with plenty of subprojects. In this blog post, we will explain what you can expect from this preview version and how the Android Studio and Gradle team achieved these improvements. Before diving into this let’s look back at what goals led to the creation of the current Android build system.
The Complexity of Mobile Development
Developing mobile applications is inherently more complex than building traditional web or server applications of similar size. An app needs to support a wide array of devices with different peripherals, different screen sizes, and comparatively slow hardware. The popular freemium model adds another layer of variety, requiring different code paths for free and paid versions of the app. In order to provide a fast, slim app for every device and target audience, the build system needs to do a lot of the heavy lifting up front.
To improve developer productivity and to reduce runtime overhead, the Android build tools provide several languages and source generators, e.g. Java, RenderScript, AIDL and Native code. Packaging an app together with its libraries involves highly customizable merging and shrinking steps. The Android Studio team was faced with the challenge of automating all of these without exposing the underlying complexity to developers. Developers can focus on writing their production code.
The build cache reuses the outputs of Gradle tasks locally and shares task outputs between machines. In many cases, this will accelerate the average build time.
The build cache is complementary to Gradle’s incremental build features, which optimizes build performance for local changes that have not been built already. Many Gradle tasks are designed to be incremental, so that if the inputs and outputs of the task do not change, Gradle can skip the task. Even when the task’s inputs have changed, some tasks can rebuild only the parts that have changed. Of course, these techniques only work if there are already outputs from previous local builds. In the past, building on fresh checkouts or executing “clean” builds required building everything from scratch again, even if the result of those builds had already been created locally or on another machine (such as the continuous integration server).
Now, Gradle uses the inputs of a task as a key to uniquely identify the outputs for a task. With the build cache feature enabled, if Gradle can find that key in a build cache, Gradle will skip task execution and directly copy the outputs from the cache into the build directory. This can be much faster than executing the task again.
We are excited to announce the release of Gradle Enterprise 2017.1. This release includes many new features and bug fixes, further expanding the build insights that build scans provide you and your team. Here are some of the highlights of this release. Contact us if you’re interested in a demo or a trial.
Easily find changes to dependencies between two builds
Dependency changes between builds can be a common source of problems. For example, upgrading a version of one library can unintentionally bring in different versions of transitive dependencies into your project. In turn, these newer versions can cause you all kinds of frustration by breaking compatibility with other libraries that your project uses.
The new build comparison feature allows you to quickly find dependency changes between builds, including differences in transitive dependencies.
We are very proud to announce that the newly released Gradle 3.4 has significantly improved support for building Java applications, for all kind of users. This post explains in details what we fixed, improved and added. We will in particular focus on:
Extremely fast incremental builds
The end of the dreaded compile classpath leakage
The improvements we made can dramatically improve your build times. Here’s what we measured:
The benchmarks are public, and you can try them out yourself and are synthetic projects representing real world issues reported by our consumers. In particular, what matters in a continuous development process is being incremental (making a small change should never result in a long build):
We are pleased to announce that version 2.0 of Buildship—our official Gradle support for Eclipse—is now available via the Eclipse Marketplace. This release adds support for composite builds, greatly reducing development turnaround time. The UI has been redesigned based on plenty of community feedback during the 1.x line. Project synchronization is now more accurate and project import requires one less step. We’ve added support for Gradle’s offline mode (thanks Rodrigue!), and last but not least, third-party integrators can take advantage of our new InvocationCustomizer extension point. Read on for details about each of these new features.
Composite build support
What is a composite build?
The composite build feature in Gradle allows you to handle several distinct Gradle builds as if they were one big multi-project build. This dramatically shortens the turnaround time when you need to work on several projects that are normally developed separately.
Let’s assume you have written a Java library lib, used by many of your applications. You find a bug which only manifests itself in the special-app. The traditional development workflow would be to change some code in lib and install a snapshot into the local repository. Then you would have to change the build script of special-app to use that new snapshot and check if the bug is actually fixed.
Build scans are a great way to easily share data about your build, but what if your team wants to add their own data to those build scans? They can! In addition to the extensive information automatically captured in build scans, you can attach your own custom data to provide even deeper insights into your build. This custom data can take the form of tags, links, and arbitrary custom values in a key-value format.
By adding custom data to your build scans you can make it easy to find builds of a certain type, give quick links to the applicable source code commit on GitHub, add helpful CI build information, and much more. Then, when you share the single build scan link with a teammate, they get quick and easy access to a plethora of information about your build, making it easier for them to diagnose build environment issues, fix test failures, and so on.
It’s not every day that we get to announce a feature that revolutionizes several software engineering workflows, but today is that day. Composite builds, a new feature in Gradle 3.1, enables an entirely new dimension in project organization.
Composite builds are a way to join multiple independent Gradle builds and build them together. The brevity of that statement does not fully convey all of the new possibilities, so let me show you how this will make your life as a developer a lot easier.
Joining projects
Many organizations split their code base into several independent projects, each having a dedicated repository and release cycle. Integration between the projects is managed using binary dependencies, e.g. JAR files published to a binary...
A few months ago at this year’s Gradle Summit conference, we announced a new part of the Gradle platform called Gradle Cloud Services. In this post, I want to introduce you to the first of these services—the Gradle Build Scan Service—and the build scans it makes possible.
What is a build scan?
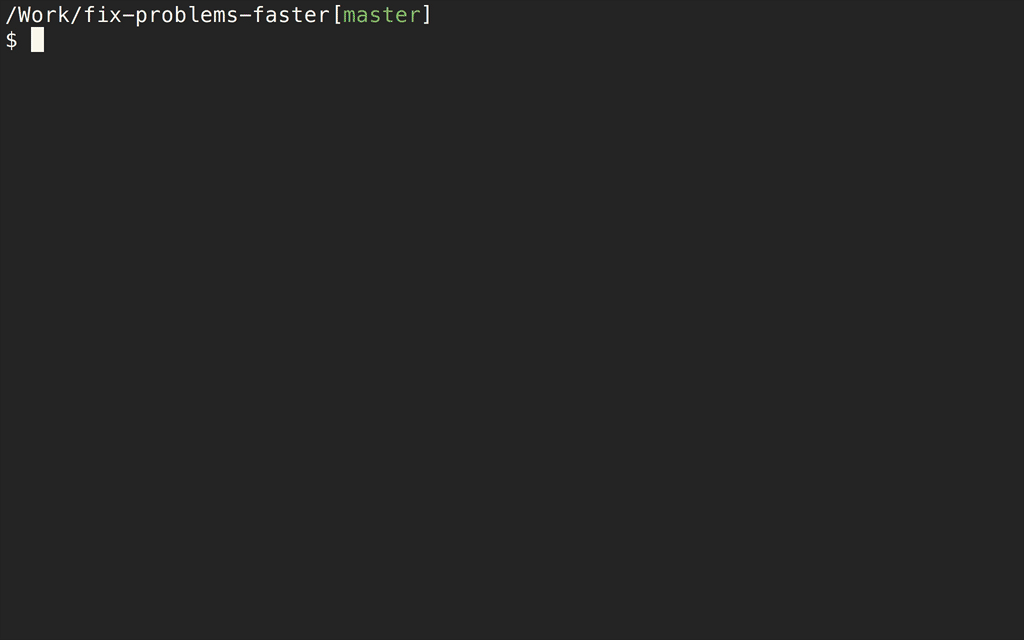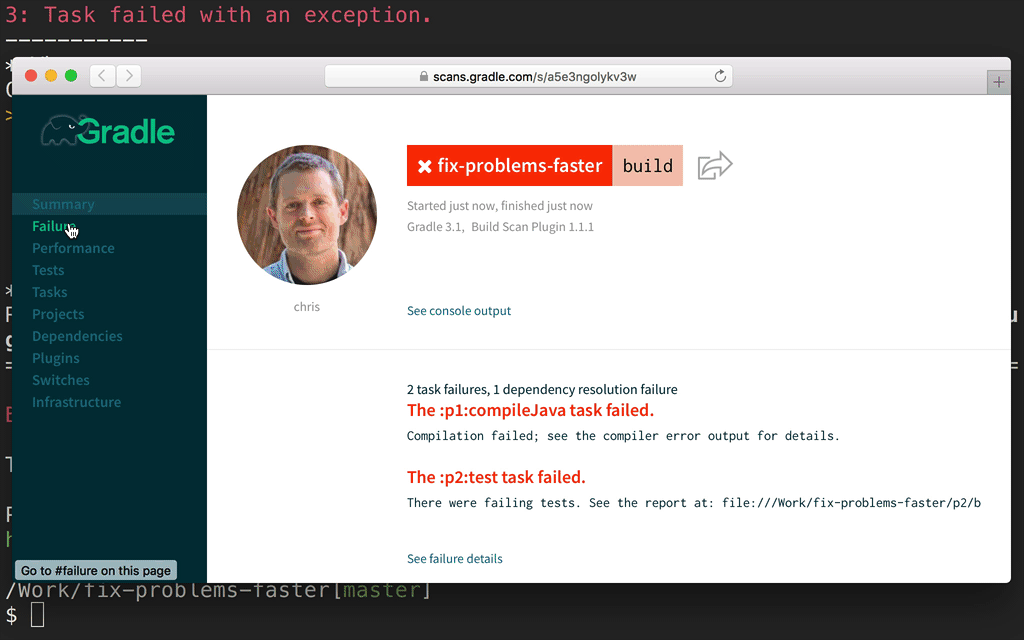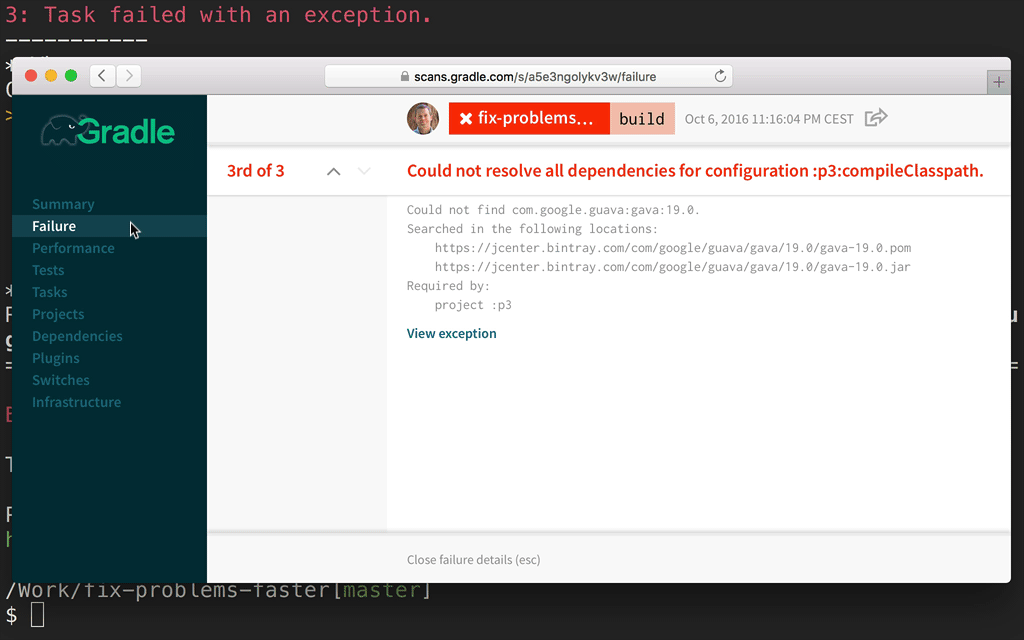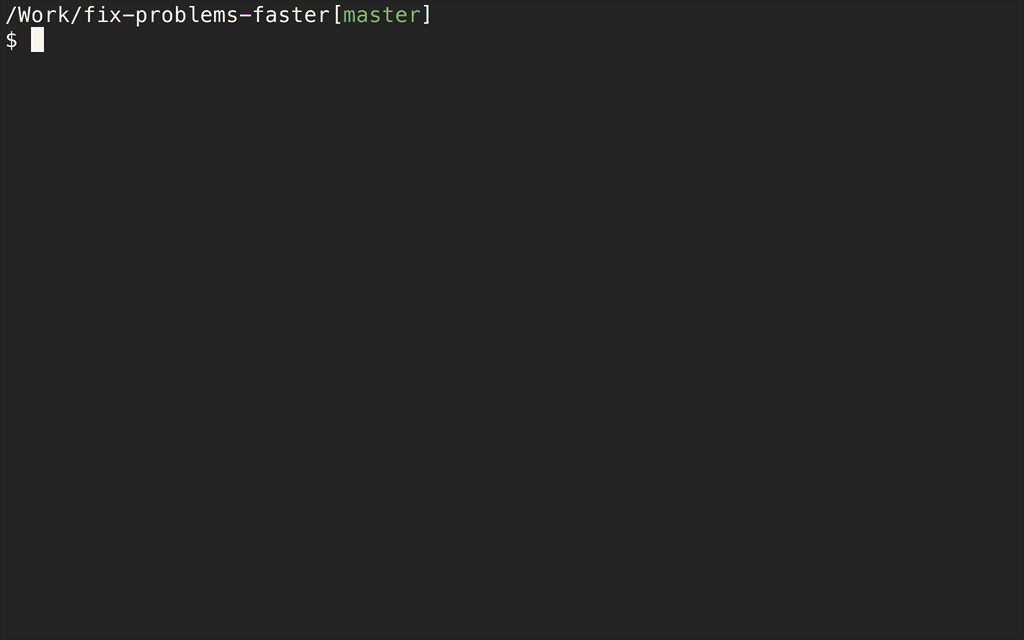
A build scan is a representation of data captured as you run your build. The Build Scan Plugin does the work of capturing the data and sending it to the Build Scan Service. The service then transforms the data into information you can use and share with others. Here’s a quick example of using a build scan to investigate a failure:
The second milestone of Gradle 3.0 has just been released, and this version comes with initial support for Java 9!
It means that Gradle now runs properly when executed on the latest Java 9 EAP builds, but also that you can build and run tests using early versions of JDK 9. It is however important to understand that while you can compile and test applications with JDK 9, we do not support modules, nor any JDK 9 specific compile options (like -release or -modulepath) yet. However we would gladly appreciate any feedback with your own projects.
Many readers will be familiar with JetBrains’ excellent Kotlin programming language. It’s been under development since 2010, had its first public release in 2012, and went 1.0 GA earlier this year.
We’ve been watching Kotlin over the years, and have been increasingly impressed with what the language has to offer, as well as with its considerable uptake—particularly in the Android community.
Late last year, Hans sat down with a few folks from the JetBrains team, and they wondered together: what might it look like to have a Kotlin-based approach to writing Gradle build scripts and plugins? How might it help teams—especially big ones—work faster and write better structured, more maintainable builds?
At Gradle Inc., we take build performance seriously. While we bundle performance improvements into every Gradle release, we’ve kicked off a concerted effort called a performance burst from Gradle 2.13 in order to make building software faster and more enjoyable for all of our users. In this blog post, we will explore how we approach performance issues, as well as what improvements to expect in the 2.13 release and beyond.
The fastest thing to do is nothing
Building software takes time, which is why the biggest performance improvement is cutting steps out of it entirely. That’s why, unlike traditional build tools such as Maven or Ant, Gradle focuses on incremental builds. Why would you ever run clean when...
One of the most highly-anticipated Gradle features has just arrived in Gradle 2.12: support for declaring compile-only dependencies. For Java developers familiar with Maven, compile-only dependencies function similarly to Maven’s provided scope, allowing you to declare non-transitive dependencies used only at compilation time. While a similar capability has been available for users of the Gradle War Plugin, compile-only dependencies can now be declared for all Java projects using the Java Plugin.
Compile-only dependencies address a number of use cases, including:
Dependencies required at compile time but never required at runtime, such as source-only annotations or annotation processors;
Dependencies required at compile time but required at runtime only when using certain features, a.k.a. optional dependencies;
Automated testing is a necessary prerequisite for enabling software development practices like refactoring, Continuous Integration and Delivery. While writing unit, integration and functional tests for application code has become an industry norm, it is fair to say that testing for the build automation domain hasn’t made its way into the mainstream yet.
But why is it that we don’t apply the same proven practice of testing to build logic? Ultimately, build logic is as important as application code. It helps us to deliver production software to the customer in an automated, reproducible and reliable fashion. There might be many reasons to skip testing; however, one of the reasons that stands out is the data definition format used to formulate build logic. In...
At Gradle, we believe that maintaining developer “flow state” is essential to building good software. And because we believe flow is essential, we assert that developers should not have to leave the IDE to build, and they should not have to know what functions are being performed by the IDE and what is delegated to the build system. It is also our vision that all build logic is kept exclusively in the build system and thus all work to calculate the project configuration, to build the project, to run the tests and to run an executable is delegated from the IDE to the build system. Hence the IDE maps the projects of the build, visualizes the build models, and displays the progress...
In the past, we’ve recommended that you enable the Gradle Daemon (and parallel execution, with some caveats) to get the best performance out of Gradle. We’ve also talked about using incremental builds to speed up your build-edit-build feedback loop by skipping unnecessary work. Now there’s another optimization available—one that allows you to get out of the way and let Gradle start the build for you.
As of 2.5, Gradle supports continuous build execution, which will automatically re-execute builds when changes are detected to its inputs. There have been a few community plugins that add support for a Gradle “watch” mode that do something similar.
With Maven, the same watch functionality needs to be implemented for each plugin...
Built-in tasks, like JavaCompile declare a set of inputs (Java source files) and a set of outputs (class files). Gradle uses this information to determine if a task is up-to-date and needs to perform any work. If none of the inputs or outputs have changed, Gradle can skip that task. Altogether, we call this behavior Gradle’s incremental build support.
To take advantage of incremental build support, you need to provide Gradle with information about your tasks’ inputs and outputs. It is possible to configure a task to only have outputs. Before executing the task, Gradle checks the outputs and will skip execution of the task if the outputs have not changed. In real builds, a task...
Maven profiles provide the ability to customize build-time metadata under certain conditions, for example if a specific system property is set. A typical use case is applying certain configuration for different runtime environments such as Linux versus Windows. For example, the project being built may require different dependencies on these different platforms.
Implementing build-time profiles in Gradle projects
If you think about it, Maven profiles are logically nothing other than limited if statements. Gradle does not need a special construct for that. Why is this? Gradle utilizes a programming language, not XML, to define the build model. This gives you the full range of expression available in a programming language to define your criteria for certain parts of...